Slice-based learning 的目的是为了提高模型在特定的数据子集上的表现。
正常模型的学习目标是优化模型在整个数据集上的指标,而有时候我们想在此基础上,提高模型在一些特定的重要数据子集上的指标。 因为在实际应用场景中,除了模型整体的表现,我们也关注甚至更关注模型在一些重要的子集上的表现,这些数据子集通常出现频率少但又格外的重要,比如自动驾驶模型中与安全相关的一些数据子集(如检测路上的骑自行车的人)。而 Slice-based learning 的目的就是为了提高模型在这些特定的数据子集上的表现。
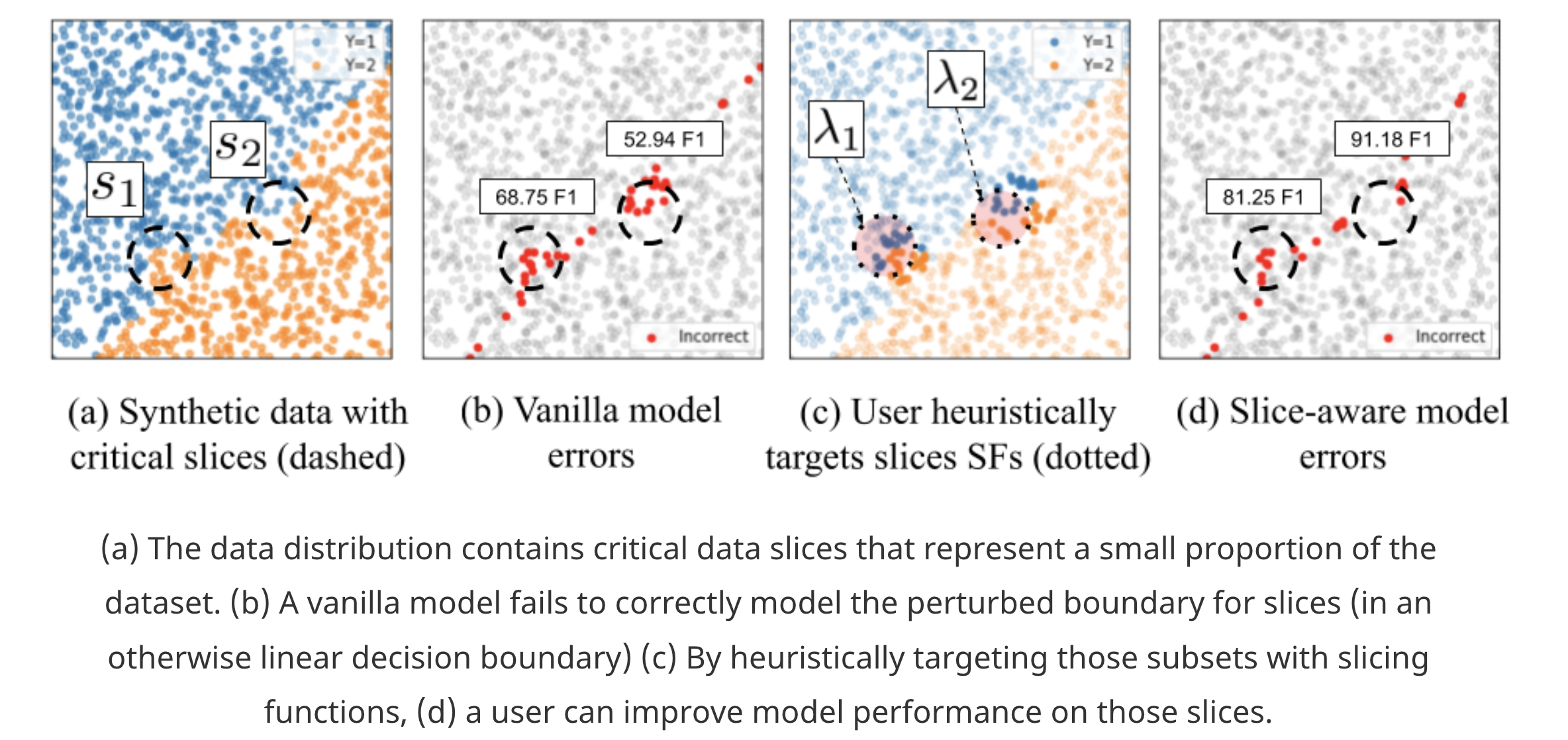
要提高模型在特定数据子集上的表现首先一个问题是如何划分数据子集,划分标准可以是基于经验,通过写一些规则,通过简单的分类器,也可以通过 error analysis 得到,我们定义 k 个 Slice Function (SF), 相当于 k 个 binary classifer,表示数据是否属于当前 slice。这个 SFs 不一定要很完美,事实上也很难完美。
划分了数据子集接下来的问题就是如何提高模型在特定数据子集上的模型表现,有以下挑战:
- Copying with noise:SFs 以弱监督的方式定义,模型需要对这些存在噪音的数据有足够的鲁棒性
- Scalability:当增加 slices 的时候,不能增加太多的参数
- Stable improvement of the model:slices 增多的时候,不能伤害现有的 slice 以及整体的 performance
这篇 paper 的思路是 专家组合(Mixtuer-of-Experts, MoE) + multi-task(MTE),在每一个 slice 训练单独的模型(即专家模型),然后用 gated function 融合各个模型输出,相当于 ensemble 的做法,麻烦的是参数利用率低,scalability 差,有多少 slice 就需要训练多少个单独的模型。而相应的,MTE 可以通过参数共享,对每个 data slice 训练单独的 task head,计算效率高,但是这样一来并不能跨 slice 共享数据,另外 MTL 中多个任务各不相同,而在 slice-based learning 中,基本任务是由相关的 slice task 来补充完善的。
于是就有了下面这个框架:
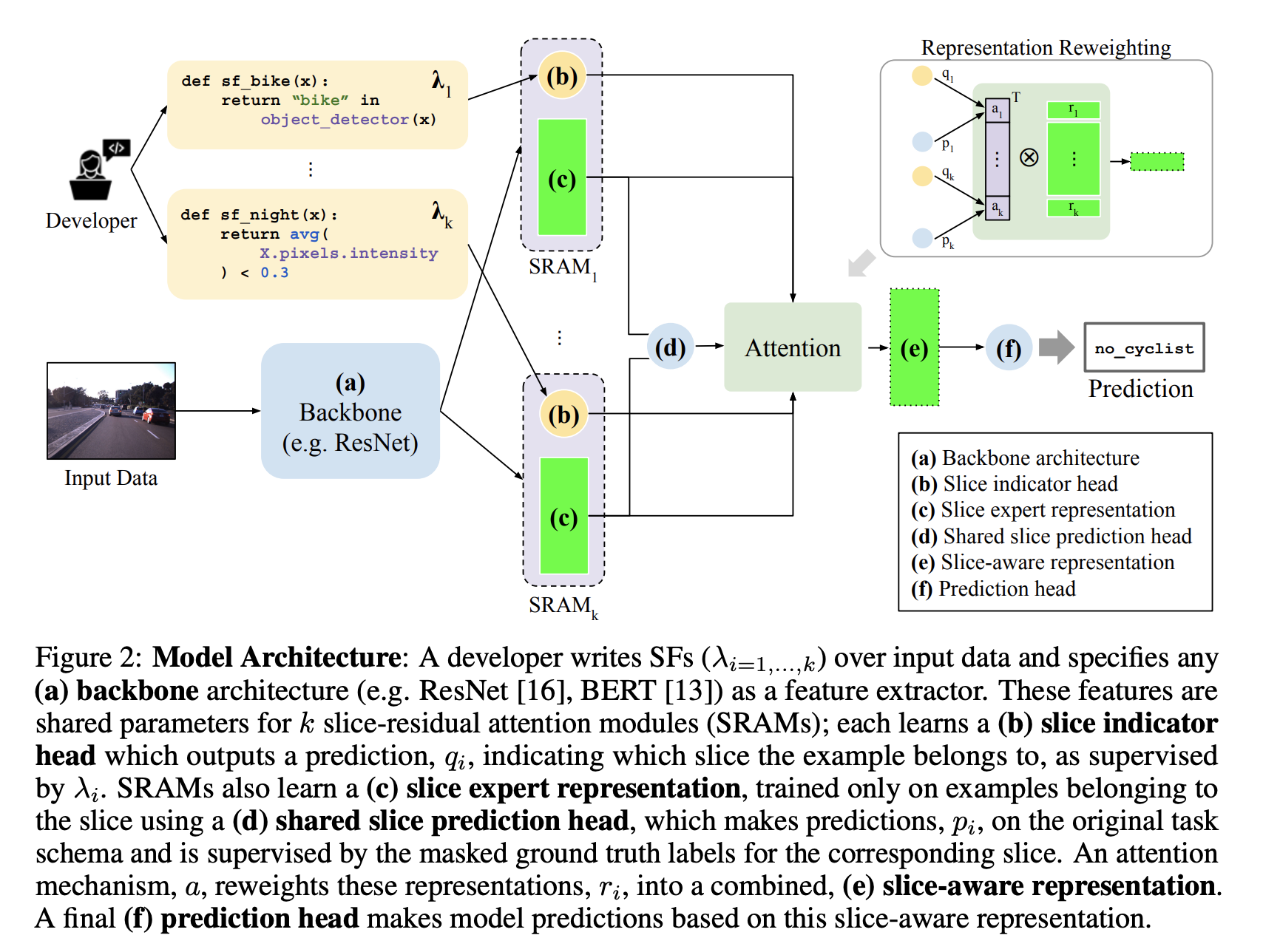
我们想训练一个标准的预测模型,称为 base task,对每个 slice,我们学习 expert representation,然后用 gated function 来组合这些 expert representation 得到一个 slice-aware representation,做出 final prediction。
(a) Backbone: 用来提取特征的模型,比如说 BERT,把输入数据 x 映射到 z
(b) Slice indicator heads: 每个 slice 对应一个 indicator head,作用是预测输入数据是否属于这个 slice,输入是 z,输出是 logits q,监督信号是 SF 的输出
(c) Slice-specific representations: 对每个 slice,学习一个 expert feature,输入是 z,输出是 r
(d) Shared slice prediction head: 共享的 slice prediction head,把各个 slice expert feature r 映射到 logit pi,只在属于这个 slice 的数据上训练,监督信号就是 base task 的真实标签 y。用共享的 head 可以保证 expert head 的输出具有一致性,便于后面的加权组合
(e) Slice-aware representation: 把 (b) slice indicator output Q 和 (d) prediction head confidence P 做 element-wise,作为 attention 权重来 re-weight 各个 slice 的特征 (c) ,得到 slice-aware representation z’,这一步也体现了对噪声 slice 的 robustness,如果某个 slice indicator 或者 prediction task 做出了置信度低的预测,那就下调它对应表示的权重
注意这一步的时候初始化了一个 base slice,base slice 包含了所有的输入数据,并且有对应的 indicator qbase,和 predictor pbase,目的是显性的来建模从 slice representation 到 base representation 的残差,所以 Q 和 P 其实包含了 k+1 个 vector
(f) Prediction head: 输入是 z’,得到最后的输出,监督信号就是 base task 的真实标签 y
loss 是 (b)(d)(f) 三部分 loss 的相加。实验结果就不贴了,读 paper 吧~

